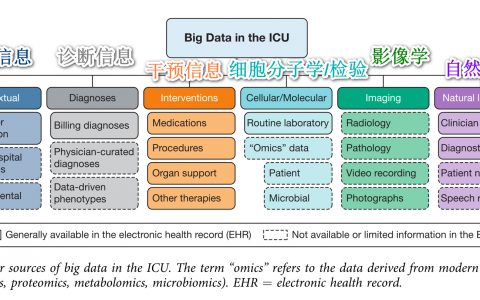
重症监护病房(ICU)数据驱动的人工智能(AI),即所谓的机器学习的研究和开发正处于历史最高水平。数据科学家和医生正在广泛的领域探索机器学习的潜力,包括感染管理。从数据科学和医学的角度来看,ICU的感染管理是一个有吸引力且颇具挑战的研究课题,这是一个高度复杂的领域,来自多个不同医学专业和资源的信息必须在单个患者身上进行整合。同时,优化ICU感染管理在临床有迫切的需求,对患者来说,及时和适当的治疗决定了病人的生存;对社会来说,抗菌素耐药和治疗不足会导致患病率和死亡率增加,因此增加了整个社会的成本。基于证据、数据生成和自动化的人工智能支持有望帮助ICU临床医生和抗菌药物管理团队采取下一步措施以解决这些问题。尽管AI在ICU的主要研究焦点是脓毒症的发生及其预后预测,以及最近的几乎所有冠状病毒疾病(COVID-19)的方方面面,但在感染管理领域也取得了重要进展。本文概述人工智能/机器学习在抗菌药物感染管理的不同领域的研究现状,阻碍临床应用的障碍,以及床边使用的注意事项。我们以抗菌药物管理周期为框架,采用务实的方法编写了一份叙述性综述(图1)。

抗生素的启动
预测感染
大量人工智能/机器学习模型已经被开发出来,试图提前预测事件的发生,通常被称为“预警”。呼吸机相关性肺炎(VAP)、中心静脉相关性血流感染(CLABSI)以及多重耐药病原体定殖/感染风险只是已经开发的预测模型的几个案例。然而,目前脓毒症和/或脓毒症休克的预测在这一领域占主导地位,Fleuren等人在其最近的系统评价中发现,仅在ICU开展的研究至少有15篇回顾性论文和1篇前瞻性干预性研究。在这些和其他预测模型中,最常见的是从回顾性数据库中例行收集的医疗保健数据(例如,病史、临床参数、生物化学结果等)开发机器学习模型,来推断未来的风险。预测模型背后的基本原理是,如果医生意识到即将发生的事件,临床过程可以改变。由于预测可被视为可采取的预防性行为,临床医生可以提前处理已知的风险因素,从而避免事件的发生。例如,当模型预测超过某个CLABSI风险阈值时,可预防性更换或移除导管,从而将发生CLABSI的风险降到最低。然而,从临床角度来看,其他预测并不能起到预防作用。例如,VAP或脓毒症高危患者除了目前采用的标准预防措施已经解决的风险因素外,没有其他已知可采取行动的风险因素。初步看来,这些预测模型不能帮助预防感染的发生,但可以用来提醒医护人员密切监测患者即将发生的感染,从而促进及时开始适当的治疗。因此,这些模型可以被归类为早期检测或“临近预测”模型。Shimabukuro等人在一项前瞻性干预研究中阐述了这一概念,在该研究中,干预组由机器学习算法监控,当识别出患者存在严重脓毒症风险时,该算法会向主管护士发出警报。该机器学习模型能够在严重脓毒症发生前4小时做出预测。在本研究中,与单独使用基于电子健康记录(EHR)的严重脓毒症检测表相比,使用机器学习算法联合使用严重脓毒症检测表的患者死亡率和住院时间显著降低。这些发现提出了一个根本的问题:我们是否可以根据高精度的机器学习模型预测,通过预先选择高危感染风险患者进行抢险治疗,从而降低感染/败血症相关的发病率和死亡率。
感染诊断:患者监测及提高诊断准确性
ICU中的感染很好识别,而且诊断也很简洁。其他感染类型因感染的标准不同,临床过程更微妙,因为诊断标准存在异质性,使其诊断对临床医生的解释更敏感。以VAP为例,临床症状、生物化学结果、放射学异常和微生物学特征的不同组合可以导致相同的诊断。当疾病标准依赖于人类评估时,人工智能的协助有可能提高解释的客观性,从而提高诊断的准确性。Hwang等人将机器学习算法添加到人类读取胸部X光片中,从而提高了非放射科医生和放射科医生的诊断性能和准确性。机器学习的应用并不局限于已建立的诊断程序,新的诊断方法也与机器学习相结合,以增强它们。例如Chen等人探索了将电子鼻传感器信号与机器学习结合用于VAP诊断的可能性,并取得了良好的准确性。
对于早期感染检测或临近预测,电子系统已经在临床实践中用于患者自动监测和医疗相关感染(HAI)的早期诊断。然而,大多数软件包是基于人类设计分类感染存在或缺席,因此不考虑发展的连续体,是典型的感染(图2)。Moni-ICU更先进的方案,即首先一定程度的兼容性(也就是说不兼容、部分兼容和完全兼容)是通过使用模糊集在观察/测量的患者数据和临床概念之间进行表达(例如,测量的血压和心率之间的兼容性,以及休克或血压下降的概念)。随后,这些临床概念的组合将通过模糊规则与更高阶概念(如:血流感染)进行评估。最终,这将导致对患者进行“正常”、“临界感染”或“绝对感染”的分类,从而及早识别处于“灰色地带”的患者。

图2 感染诊断检测技术的发展。目前临床对感染的检测通常处于感染发展的后期(红线)。基于规则的硬编码的早期检测自动监测系统(RBSS)只在感染的临床阈值已通过时才诊断感染。基于模糊的监测系统能够识别临床前感染区(“灰色地带”)的患者,而临近预测模型可以在感染尚未被临床诊断时进行预测。因此,与目前的临床实践相比,采取先发制人的措施或开始适当的抗生素治疗可以获得更大的治疗空间。O给定时间的患者状态,基于RBSS规则的监测系统,CP当前的临床实践
炎症与细菌感染的鉴别
从抗生素管理的角度来看,最困难但也是最重要的是如何区分病人是真的感染或只是没有任何感染的全身性炎症。区分这两种疾病状态需要整合不同类型的数据,但没有一种数据具有高度的敏感性和特异性,因为在这两种疾病状态中,这些变量的异常值都很常见,目前缺乏高度鉴别性的指标。然而,Lamping等人已证实一种基于随机森林的机器学习方法,使用8个常规可用参数,在鉴别危重儿童的感染与非感染状态方面优于目前可用的生物标志物。该模型对临床完全诊断为脓毒症的患者进行诊断,正确地对28%的非感染性病例进行了分类。如果外部验证和临床试验都证实了该模型的有效性,这可能大幅度减少不必要的抗生素应用。最近的一个例子是,在COVID-19大流行期间区分炎症和细菌感染是很困难的,很难诊断来自细菌的合并感染。Rawson等应用机器学习模型,仅使用常规血液检测结果来判别细菌感染的诊断。该算法的前瞻性评估正在进行中,但54例患者的受试者操作曲线(AUROC)下的初步面积(AUROC)为0.96,令人鼓舞。
启动抗生素治疗
今天,抗生素应用要么根据临床经验,要么根据临床培养的结果。无论哪种情况,致病病原体都是未知的。此外,病原微生物的抗生素敏感性只有在抗菌素治疗开始后很久才知道。理想情况下,从临床样本行快速诊断得到的致病微生物的鉴定和药敏结果需要大约30min,这将大大减少经验性治疗的需求或在使用第二次抗生素应用之前便可及时进行调整,从而使得治疗更加及时和准确。在这个领域,研究人员已经表明人工智能/机器学习同样可以发挥作用。
提高可用的技术
机器学习的应用已被研究,用以加强可用的表型、病原体基因型和耐药性鉴定技术。例如:Roux-Dalvai等人开发了一个蛋白质组学库,用于鉴定尿路感染最常见的15个菌属(占84%的尿路感染),使用液相色谱和串联质谱技术与机器学习相结合,可无需培养在4h内做出诊断。在另一项研究中,Feretzakis等人测试多个机器学习模型,只需要有限的信息(包括标本的来源,可能的感染部位,病原微生物革兰氏染色和以前的药敏数据)来预测对特定抗生素的敏感性,在ICU患者中获得了72.6%的准确度。但从临床角度来看,最有前途的研究是由Ho等人进行的,他们结合了血液样本的拉曼光谱(Raman spectroscopy)和深度学习,为全世界ICU中最常见的30种细菌和真菌开发了一个基本分类模型。这个方法只需要10个细菌细胞就可进行检测,病原体和耐药性鉴定方面表现优异,而且研究还表明,初始模型可以随着新的拉曼光谱的添加而不断改进。作者认为该技术可在几个小时内处理血液、痰或尿液样本,不需要孵育期,该技术有可能大大缩短抗菌素耐药性病原体的识别时间,对某些感染有非常高的准确性。
药物敏感性预测
尽管大大减少了病原微生物鉴定时间,但上述技术仍然需要采样和样品处理,因此将并不能立即指导抗菌素选择。另外,目前也在研究能够在取样时帮助预测致病微生物和/或抗菌素耐药性的模型。预测模型已经开发出来,主要使用监督机器学习,主要对那些取样之前或之后收集的那些常用临床监测数据和标本进行分析。使用这种方法已经对各种样本类型、感兴趣的病原体和关注的抗菌素进行了调查,并取得了不同程度的成功。一些模型的优势是在低收入和中等收入国家的实施潜力。例如,Oonsivilai等人在柬埔寨儿童医院进行的一项研究测试了多个机器学习模型,以预测革兰氏染色的结果和病原体对氨苄西林和庆大霉素的敏感性,使用头孢曲松或不使用头孢曲松,仅使用来自临床和人口统计数据的变量以及关于其生活条件的信息。该最佳模型具有良好的预测性能,革兰氏染色结果的曲线下面积(AUC)为0.71,头孢曲松敏感性为0.8,氨苄西林和庆大霉素敏感性为0.74,对上述抗菌药物的耐药性为0.85。
抗生素剂量和给药间隔
定量药理学历来通过线性回归、群体药代动力学模型和贝叶斯预测来指导剂量和给药间隔。开发的模型大多仍处于研究阶段,试图作为给药软件进入临床,但缺乏广泛的实践检验。将机器学习引入定量药理学仍处于起步阶段,但双方合作的潜力正日益得到人们的认可。与此同时,机器学习研究正在改进抗生素的剂量,如Huang等人开发的XGBoosting万古霉素剂量预测模型。但由于误差较大,在临床应用中仍需进一步探索。
抗生素治疗期间:机器学习与微生物实验室检测
与定量药理学领域相比,机器学习的应用正在微生物实验室的各个方面进行探索。我们参考了peifer-smadja等的论文对这一主题进行深入分析。从光谱数据和转录组学的显微图像到基因序列,一切都是不遗余力。一般来说,大多数模型的目标是微生物鉴定/量化和耐药性评估,以减少周转时间。例如,Inglis等人证明了监督机器学习可以通过使用流式细胞仪辅助的抗生素敏感性测试生成的数据,加快抗生素耐药性的识别。他们的模型能够在血培养阳性后3h内产生预测的抑制浓度,而标准方法在培养阳性后大约24小时。通过将机器学习与红外光谱相结合,Lechowicz等人能够将测试时间进一步降低到30min,值得注意的是,基于人工神经网络的机器学习模型并没有获得完美的分类结果。
支持抗生素药物管理
近年来,医院在制定和维护自己的抗生素药物管理规范投入了极大的精力。这些抗生素管理规范的实施已经对住院时间和抗生素应用产生了重大影响。抗生素管理规范的一个基本要素是抗生素处方审查和处方反馈,其中对抗生素处方的几个关键参数(例如,适应症、剂量、给药途径、持续时间)进行评估。如果认为有必要修改,则由审查人提出建议。这是一项耗时的工作,计算机系统经常被用来帮助确定需要复查的病人。然而,应该指出的是,这些临床决策支持系统(CDSS)通常有一个专家和基于规则的知识库,这使得开发和维护这些系统以改变指南也是时间和资源密集型的。此外,资源的限制导致只是挑选出某些感兴趣的抗生素,而不是评估所有处方抗生素。为了克服这些缺点,Bystritsky等人尝试开发线性回归和增强树模型,使用常规可用的医疗保健数据来识别可能受益于处方审查和处方反馈的患者。虽然这些回顾性开发的模型的区分能力是公平的,需要通过模型进行审核以确定需要干预的患者的数量很高,但所有使用处方抗菌药物的病人都可以通过自动化的方式进行评估,这一前提可能会产生巨大的优势。另一种方法是将目前可用的CDSS抗菌管理系统与机器学习相结合。来自Université de Sherbrooke的研究人员证明,他们的监督学习模块可以通过评估临床药师过去的推荐,识别出与临床相关的新规则,对已有知识库进行补充。尽管前景广阔,但将通过机器学习学习到的新规则整合到现有的知识库中并自动化规则维护仍然是一个重要的挑战。
停止抗生素应用
未来方向
基于上述信息,尽管程度不同,人工智能和机器学习研究越来越多地与抗生素管理循环的各个方面交织在一起。然而,由于大多数模型仍处于设计/原型阶段,或仅在内部临床数据上进行了测试,因此临床中也只是零星应用。在外部数据集实施和临床试验之前,对这些模型进行验证将是至关重要的,而充分设计这些试验将是一项挑战。选择基于基本事实的客观模型(例如,抗菌药物浓度的预测)作为正确的参考标准,比为人工解释和主观判断(例如,VAP的诊断)确定该标准更为简便。与此同时,我们必须做出决定,作为临床医生,根据给定的任务,我们认为什么样的表现水平才足以将一个模型成功用于临床实践。只要我们不能纳入近乎完整的因果性病理生理的过程变量,那么期望机器学习模型完美无缺是一个乌托邦式的梦想。完美的模型将是不太可能的,即使是最客观的实际实况,重复测量也可因测量方法而发生改变(例如,高性能液相色谱串联质谱抗菌浓度测定时between-run和within-run的不精确性)。
其他需要解决的方面是伦理和法律责任,例如,临床医师超说明书应用,或遵循一个后来被证明是有缺陷的模型的建议。与这方面密切相关的是,需要培养医生对模型鉴别能力和对相关研究能够具有批判性思维和独立评估。由于临床医生将是这些人工智能系统的最终用户,因此需要对其进行培训,不仅要确保其使用正确,还要使医生能够正确识别和报告出现的问题。
最后,本文中提到的所有模型都有一个独立的设计,并集中在抗生素管理的一个特定方面。应该将各种工程模型以一种有意义的方式整合和管理到日常实践中,以便支持整个抗生素管理,而不是将医生束缚在屏幕上,这可能是最大的挑战。
机器学习模型实施后监控
机器学习模型在临床实践中的应用效果可以预见,这些模型的管理将成为新的任务,且不得不由临床医生承担,至少部分需要这样。作为最终用户,临床医生将成为鉴别AI犯错时的第一道防线。AI的犯错是可能的,正如Finlayson等研发的Epic Sepsis预测模型,该模型遭遇了一种称为数据集转移的现象。当机器学习系统在部署后表现不佳时,就会发生数据转移,原因是它开发的数据/背景与其应用的数据/背景不匹配。就临床实践而言,这意味着患者人口学特征的任何变化或差异,或者开发的模型的治疗方案与患者实际需要模型给予的治疗方案存在差异,都可能会使模型的治疗建议出现缺陷。这些差异或变化很容易识别(例如,不断发展的抗菌素耐药性流行病学,或新的一线抗菌素的引入),但也可能非常细微(例如,人工智能系统实施后临床医生的行为变化,或诊断测试的改变,它改变了参考值)。随着临床实践的变化比以往任何时候都要快,保持模型的准确性和更新将是一项任务,临床医生将不得不在一个超越医学之外的多学科团队中发挥关键作用,以确保患者安全。机器学习解决方案,如在线学习,可能会在这一领域发挥作用。
通过“物联网”实现个性化研究
感染的诊断过程通常由临床参数(如,体温)或实验室结果(如,CRP升高)的变化触发。对于后者,高于设定阈值以及随时间的趋势常被用于临床实践诊断。然而,对于前者,目前的指南使用刚性阈值来区分病理状态和正常状态,显然这并不适用于所有患者。例如,成人患者的发热通常被定义为温度≥38°C,而根据测量方法和患者的年龄,正常人群的范围在35.61°C-37.76°C之间。通常,老年患者在感染时不会发烧。通过“物联网”整合来自当前广泛使用的可穿戴设备的信息,新的研究机会就出现了,目的是确定在个人层面上,我们应该使用哪些阈值来识别生理参数的重大变化。向医生揭示这些基本生理特征,可以帮助在患者层面进行个性化治疗,也有助于开发机器学习模型来实现同样的目的。一些公司和医疗保健系统已经采取措施,将可穿戴健康技术数据集成到电子健康记录(EHR)中,但实际的临床效果尚未得到证实。
组学
除了人工智能和机器学习,不同类型的组学也在深入研究医疗保健的各个方面,因为人们相信,组学可能提供必要的工具,推动临床实践走向精准医疗。然而,研究组学所遇到的挑战是数据量庞大和处理数据需要的强大算力。由于人工智能和机器学习能够处理这类问题,将这两个领域结合起来可能会通过整合来自不同组学研究领域的信息来创造新的见解,正如ShockOmics研究计划所呈现的研究思路。
结论
人工智能和机器学习在ICU抗菌药物管理方面的研究方兴未艾,但迄今为止,真正的临床应用还少之又少。内部验证结果很有希望,因此在未来几年,外部验证研究和随机对照临床试验有望增加。在不久的将来,构建安全验证和实施这些模型的先决条件对临床应用来说是必要的。在新兴的跨界医学(beyond-the-borders-of-medicine)的多学科团队中,临床医生将在促进这一过程中发挥重要作用。
学术交流文章,不做为临床依据,特此声明。发布者:Chu,转转请注明出处:https://www.icu.cn/?p=4646
 微信扫一扫
微信扫一扫