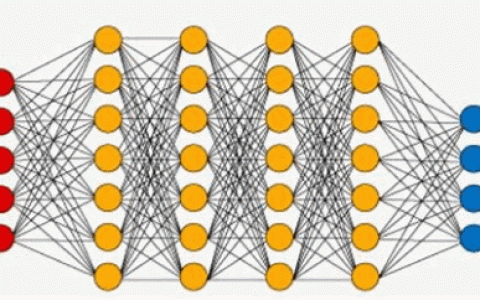
数字信息:重症监护室中的人工智能应用 Chu • 2022年4月14日 下午2:42 • 数字信息 • 阅读 2883 重症监护病房(ICU)产生的大量临床、监测和实验室数据的电子健康记录的收集及传播是人工智能应用的自然领域。人工智能的泛定义,包括计算机视觉、自然语言处理和机器学习,后者在重症监护室更常用。机器学习可以分为监督学习模型(如支持向量机[SVM]和随机森林)、非监督模型(如K-mean聚类)和强化学习。受监督的模型需要有标记的数据,这些数据是由人类根据预先定义的类别进行判断而映射的。相反,即使没有标记数据,无监督模型也可以用来获得可靠的预测。机器学习模型已在ICU中用于预测急性肾损伤等病理,检测包括谵妄在内的症状,并提出治疗措施(脓毒症中的升压药和液体)。未来,由于可用数据的质量和数量不断增加,人工智能将越来越多地用于重症监护室。因此,重症监护室团队将受益于用于研究目的和临床实践的准确性。这些模型也将是未来决策支持系统(DSS)的基础,它将帮助ICU团队可视化和分析大量信息。 循证医学逐渐被公认为现代医学的里程碑。随机对照试验位于证据讲台的最高台阶上,其设计通常利用多中心性来提高外部有效性。然而,尽管大型多中心研究仍然是金标准,但就时间和资源而言,进行这些试验既困难又昂贵。因此,现代医学中只有10%至20%的建议是基于证据的。这与重症监护医学特别相关,近年来,大量侧重于死亡率和主要临床结果的随机对照试验产生了阴性结果。上述限制与危重患者群体的特征有关,根据重症监护病房(ICU)入院时的不同条件,这些患者在共病、年龄和基线死亡率方面有很大差异。因此,重症监护中阴性试验的高频率可能与异质性和混杂效应有关。因此,重症监护室患者从一种被称为治疗效果异质性的特定治疗中获得的益处存在很大差异,这甚至可能导致明显的悖论,例如对高风险亚组有益的治疗的阴性试验。 在所有开始向大数据过渡的医院病房中,ICU是最合适的病房。这是由于监控系统的数量很大,以高粒度(即每分钟甚至每秒钟收集数据)连续收集呼吸、血液动力学、神经学和临床数据。大数据可能有助于克服应用于重症医学的循证医学的一些局限性。随机对照试验通常用于控制偏倚和混杂的风险,在病例和对照中随机分布。虽然这种策略可能对观察者引入的偏差(选择偏差、报告偏差和观察者偏差)很有效,从而降低1型错误(假阳性错误)的风险,但这种方法实际上可能增加2型错误(假阴性错误)的风险,阻碍特定亚群中阳性治疗效果的识别。在每个可能的亚群中进行随机试验所需的不可行性和成本进一步增加了2型错误的风险。相反,电子健康记录(EHR)可以轻松收集大量数据,其中包含的分辨率与护理医生做出决策时使用的分辨率相同,因此在较小的人群中进行治疗干预分析变得极其容易。 机器学习技术是为分析非常大的数据集而设计的算法。机器学习背后的概念是允许计算机学习,而不需要对特定的任务进行编程,也不需要人类理解、监督和解释数据分析的所有步骤。机器学习模型是在包含大量原始数据的数据集上训练的,并且基于数字、图像或文本。机器学习模型与标准分析模型相比的优势在于,最佳算法是由机器学习过程自动调整的,而不是由人类交互一步步编码的。在最简单的机器学习过程中,以下三个关键方面合作产生结果:数据集(包含原始数据)、算法(解释数据)和选定的特征(在数据集中选择用于分析的变量)。特征用于定义监督学习过程中的关键方面,需要人工判断和交互。相反,无监督模型的建立是为了解释信息,而不需要事先选择特征。 在重症监护医学中,最常用的人工智能算法是基于机器学习的算法,因为重症监护是通过复杂的连续监测和连续治疗获得的大量数据的良好来源。单个重症监护室入院产生的数据的复杂性,从基线患者数据开始,到严重疾病首次出现器官衰竭水平,包括从整个重症监护室入院获得的所有治疗和生物及临床数据。整个重症监护室入院时病情预测的机器学习策略可能比常用的评分(如顺序器官衰竭评估)和APACHE-II(急性生理学和慢性健康评估)具有明显的优势,因为与标准评分相比,将达到更高的性能,并代表着向个性化医学。 分类模型通常用于自动预测一个对象是类别的哪一部分。因此,该模型的目的是使用来自一些输入变量的数据,定义能够将患者分配给离散输出变量的映射函数。相反,回归模型通常用于预测一个量,即在给药后血压上升或下降多少。逻辑回归,不管它的名字如何,仍是一种分类学习算法。它使用sigmoid函数为事件分配一个概率,根据定义,该概率限制在0和1之间。它是医学上最流行的分类算法之一。然而,在临床医学中,我们很少能拥有通过线性或逻辑回归预测的简单模型。随着与越来越多的数据相关的场景的复杂性的增加,以及对现实的更好表述,需要更复杂的模型来解释数据。 机器学习算法: 监督学习模型和标记数据: 监督学习算法通常用于重症监护医学。术语“有监督的”是指从有标签的数据中学习的过程。通过训练,该算法将搜索与结果最相关的模式。决策树是一种类似流程图的模型,它通过对应于每个树节点的几个决策节点处理输入信息后产生一个结果。支持向量机SVM模型的目标是在二维空间中定义一个超平面,当二维或三维空间中的一条线或一个平面不起作用时,它能够对数据点进行分类。随机森林基于大量并行工作的单个决策树。每棵树都不同于其他树,并且独立地对结果进行分类,通过一种民主的过程,具有较高票数的分类产生最终的输出。 深度学习: 神经网络为了改善复杂信息的处理,深度学习模型试图复制人脑的结构。它们使用非线性变换来提高抽象水平,与监督模型不同,深度模型可以在没有预先标记或特征选择的情况下使用。 强化学习: 在决策序列中特别有用。当算法被训练时,在试错游戏中,算法的每一个选择都会导致奖励或惩罚,这使得能够在不确定的环境中解决复杂的问题。该算法试图使奖励最大化,减少惩罚。程序员设定奖励和惩罚,但没有给出如何解决问题的建议。 人工智能在重症监护中的力量可以通过两个步骤释放出来:临床决策支持系统和精确医学。在未来,通过建立在数千个特征上的机器学习算法得到的决策支持系统可能构成一个主要的临床优势。 尽管人工智能临床医生有其主要优势,但他们也有一些重要的局限性。对于一个算法来说,在它的决策过程中包含影响每个病人个人选择的大量意见和信念是非常困难的。此外,机器学习模型可能会发现虚假的关联,并错误地将其解释为事件之间的真实关系。大多数关于病人护理的临床知识是通过临床图表中的自然语言或在同事之间的口头交流中传播的,这些仍然被排除在人工智能算法之外。 详细内容放在微信公众号:https://mp.weixin.qq.com/s/YbB-btUtln3SGVSEhe0zsg 学术交流文章,不做为临床依据,特此声明。发布者:Chu,转转请注明出处:https://www.icu.cn/?p=3360 人工智能信息网络 赞 (0) 打赏 微信扫一扫 Chu 0 0 生成海报 编程参考:postgresql安装报错:Failed to load sql modules …… 上一篇 2022年4月14日 下午2:34 mimicivd的相关字段和数据集 下一篇 2022年4月15日 下午2:49 相关推荐 数字医疗 深度学习2:反向传播算法原理 3.7K000 Chu 2023年5月17日 数字信息 在危重患者中基于深度学习的复发性谵妄的预测 1.4K000 Chu 2023年4月7日 数字信息 我认为 web3 是什么(大白话 web3) 2.2K000 Chu 2022年5月25日 数字信息 使用机器学习对ICU血流动力学干预的早期预测 1.4K000 Chu 2023年4月30日 开发参考 密码保护:基于器官功能障碍轨迹的脓毒症亚型 6.8K000 Chu 2023年5月10日 开发参考 主要机器学习算法概述 891000 Chu 2023年5月10日







 微信扫一扫
微信扫一扫