决策树的基本原理
决策树是什么?
决策树是数据科学领域最为经典的模型之一,也是一种应用非常广泛的分类方法。
在日常生活中,我们经常会通过对一系列问题的判断来进行决策。例如,风险投资、相亲择偶、医生问诊,其实都是一个决策的过程。
医生会通过观察、询问、体检来获得患者的基本症状,然后选择不同的维度,依据自己的经验规则,对患者的病情进行诊断。
在银行贷款时,银行的信贷审批员也需要根据借贷人的基本信息如收入、教育程度、婚姻状态等信息对是否放贷进行决策。
男女相亲时,双方可能会根据对方的外貌、教育程度、收入、性格等信息,决策是否进一步交往。
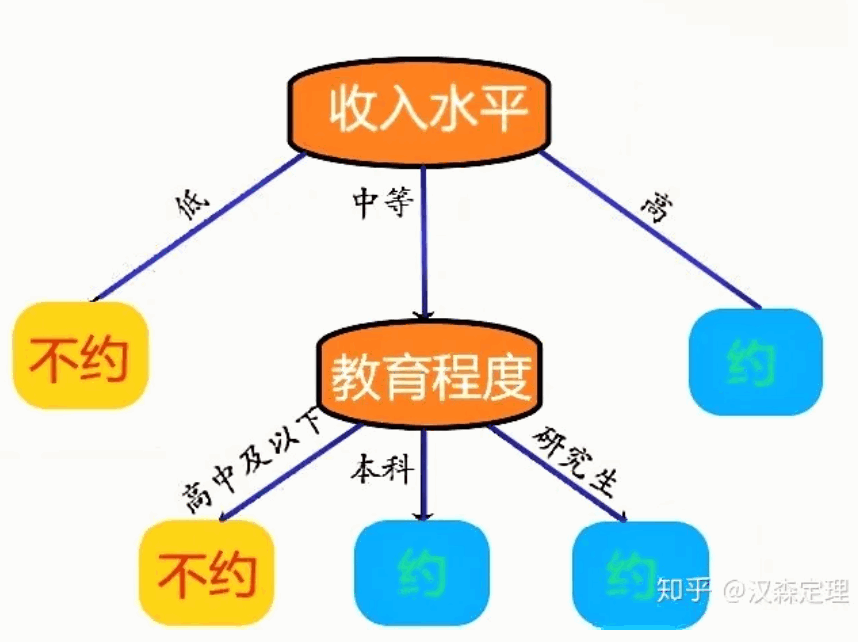
如果女方比较看重男方的收入和学历,则女方判断是否约会依据的规则可能有:
规则1:若男方收入高,则约。
规则2:若男方收入中等且为本科或研究生学历,则约
规则3:若男方收入中等且为高中及以下学历,则不约
规则4:若男方收入低,则不约。
这样四条规则就可以把是否交往这个问题从收入和教育程度两个维度进行了划分,这些几条决策规则可以用一个树形结构表示可以表示,如下图所示。
医生、天使投资人、信贷审批员、找对象的女生头脑里都有一些专家规则,这些规则往往是通过非常多的案例归纳或者其他人的言传身教逐渐形成的。但是,很多很多时候,我们并没有这样的专家决策系统,而只有数据。如果你是一个女生,注册了某个婚恋网站的会员,婚介一次性给你推荐了10个备胎,如下表所示,你选择与其中5个人约会,另外5个你选择不约。
对象编号收入水平教育程度颜值年龄身高是否约会1低研究生高28178不约2高本科中等35185约3低高中及以下中等30170不约4中等高中及以下高28175不约5低本科高40165不约6中等本科低27180约7中等高中及以下低25182不约8中等研究生中等50168约9中等研究生低38177约10高高中及以下高24172约
于是,我们从收入水平、教育程度、颜值外貌、年龄、身高以及你的决策结果几个维度收集到了这些人的数据,我们能否从这些数据中能否学习到一些规则,构建一个交往决策系统,决定你会与哪些人约会,然后更精准地给你推荐相亲对象呢?这就是决策树所要解决的问题。那么如何根据已有数据生成决策树呢?这就是下一节所要讲的内容。
决策树的生成
决策树中的每一个非叶子节点(如收入,教育程度)代表在某个特征上的一次判断。每一次判断都包含两个层次的问题:
- 一是对哪个特征进行判断,例如对收入进行判断。
- 二是在该特征上进行怎样的判断,收入“高”?收入“低”?收入“中等”?。
树中的叶子节点(如约,不约)代表决策的结果,决策结果是根据树的根节点到该叶子节点的路径上的一系列判断来决定的。
决策树的生成一般是从根节点开始,选择对应特征,然后选择节点对应特征的分割点,再根据分割点分裂节点。
对于离散型特征,根据取值进行分裂,如相亲对象这一数据集中的“颜值”是一个离散型的特征,其有三个取值——“高、中、低”,那么根节点就分裂成三个子节点。
对于连续型特征,则需要根据取值的分割点,来分裂子节点,例如“身高”这一特征,可以选择170作为分割点。
总而言之,决策树通过选择特征和对应分裂点生成多个子节点,当某一个节点中的取值只属于某类别(或方差较小)时,那么就不再进一步分裂子节点。
核心问题:如何选择节点的特征以及特征分割点?
要回答上述问题,我们首先介绍不纯度的概念(所谓的纯与不纯,就是你理解的那个“纯”)。
不纯度(impurity): 表示落在当前节点的样本类别分布的均衡程度,如果类别一致,那么不纯度为0。
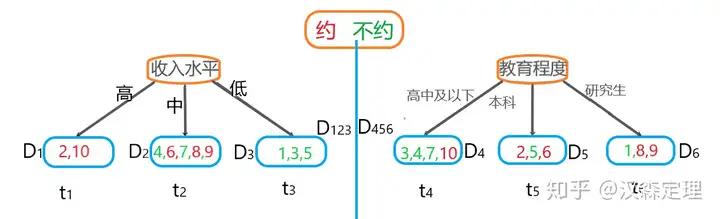
如上图所示,叶子节点t1和t3是比较纯的,叶子节点t2就不那么纯了。
我们根据不纯度的下降程度来选择特征和对应的分裂点。
假设在节点分裂前的相亲对象的数据集为D0={1,2,3,4,5,6,7,8,9,10},编号代表的是每一个相亲对象。 接下来,我们根据“收入水平”和“教育程度”这两个特征为例,来说明如何选择特征。
根据收入水平的取值“高”、“中”、“低”,将数据集分裂为三部分,分别为D1、D2和D3,记为D123,教育程度分裂后的子节点数据集分别为D4、D5和D6,记为D456。
假设Imp(⋅)为节点的不纯度。收入水平分裂节点前后的不纯度的下降值为Imp(D0)−Imp(D123)。 教育程度分裂节点前后,不纯度的下降值为Imp(D0)−Imp(D456)。 然后,比较收入水平和教育程度分裂前后不纯度下降值的大小,选择下降值更大的特征(从不纯到最多的纯)作为最优的分裂方式。
从上图可以直观看出,选择收入水平的不纯度下降是最大的。
如何度量不纯度呢?
那么,究竟如何度量节点的不纯度呢?不同决策树算法有不同的衡量指标。下面介绍三种常见的节点不纯度度量方法:
- 基尼指数(Gini index)
- 信息熵(Entropy)
- 误分率(Misclassification error)
基尼指数(分割前)
基尼指数是衡量一个国家或地区居民之间的贫富差距的指标,常用来判断社会财富分配的公平程度,这一指标实质上是反映社会中各个收入水平的人群数量分布的均衡程度。
同理,我们可以借用Gini指数来反映决策树子节点中不同类别样本分布的均衡程度,即不纯度。
假设数据集一共有C类,p(C|t)是节点t中第c类样本的相对频率,则节点t的Gini指数为
Gini(t)=1−∑c=1c[p(C|t)]2
根据基尼指数的计算公式,我们可以知道,当节点中各个类别的样本比例一致时,即均匀分布,Gini指数取得最大值(1−1C),节点不纯度最大;当节点中的样本全部属于一个类别时,Gini指数等于0,节点不纯度也最小。
相亲对象数据集的结果变量是否约会,有两个类别——约与不约,故C=2。我们可以根据一个节点t中不同类别样本的数量来计算Gini指数。
节点编号约样本数不约样本数t055t120t232t303t413t521t621
我们将t0作为根节点,我们可以根据基尼指数的计算公式,计算出分裂前的根节点的基尼指数,总样本为10个,约与不约各占5个,则Gini(t0)=1−((510)2+(510)2)=0.500。
若按照“收入水平”分裂根节点,则3个叶子节点的基尼指数计算如下:
Gini(t1)=1−((22)2+(02)2)=0
Gini(t2)=1−((35)2+(25)2)=0.480
Gini(t3)=1−((03)2+(33)2)=0
若按照“教育程度”分裂根节点,则3个叶子节点的基尼指数计算如下:
Gini(t4)=1−((14)2+(34)2)=0.375
Gini(t5)=1−((23)2+(13)2)=0.444
Gini(t6)=1−((23)2+(13)2)=0.444
我们假设n为父节点t中样本数量,节点t经过某种方式分裂后生成了K个子节点,nk为第k个子节点tk的样本数量。以每个子节点包含的样本数量占比作为权重,对子节点的Gini指数加权求和,就可以得到特征分裂后的Gini指数:
Ginisplit=∑k=1KnknGini(tk)
则“收入水平”分裂后的Gini指数为: Ginisplit=210×0+510×0.480+310×0=0.240
对于不同的分裂方式,我们总是选择使得Gini指数下降值(Gini(t0)−Ginisplit)最大的分裂方案,则按“收入水平”分裂的Gini指数下降值为Gini(t0)−Ginisplit=0.500−0.240=0.260。
则“教育程度”分裂后的Gini指数为: Ginisplit=410×0.375+310×0.444+310×0.444=0.417
则按“教育程度”分裂的Gini指数下降值为Gini(t0)−Ginisplit=0.500−0.417=0.083。
特征“收入水平”的Gini指数下降值最大,所以我们最终选择“收入水平”进行第一次分裂。
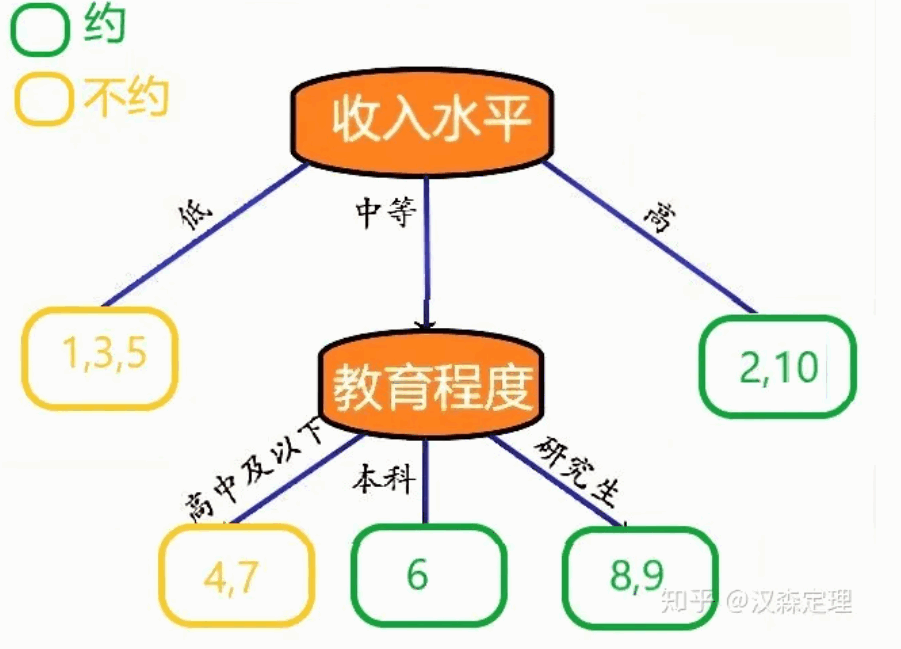
我们使用收入水平对根节点进行第一次分裂之后,发现收入水平为“中”的节点还是不够“纯”,我们需要对这个叶子节点进行分裂,这时选择特征和分割点与分裂根节点的方法是一样的,这样最终叶子节点只包含同一类样本,最终节点的不纯度都为0,则停止分裂,由此得到最终的完整决策树。如下图所示:
信息熵
信息熵这个词是Shannon(香农)从热力学中借用过来的一个概念,用以度量信息的不确定度。我们可以使用信息熵来度量一个节点样本分布的不纯度。 假设数据集一共有C类,p(C|t)是节点t中第c类样本的相对频率,则节点t的信息熵为:
Entropy(t)=−∑c=1cp(C|t)log2p(C|t)
Entropy(t)=−∑c=1cp(C|t)log2p(C|t)
当节点中的样本均匀分布在每一个类别时,信息熵取得最大值log2C,表示节点的不纯度最大。 当一个节点的所有的样本都属于某一个类别时,信息熵为0,这时该节点的不纯度最小。根节点的信息熵为 Entropy(t0)=510log2510−510log2510=1 对于收入水平的三个节点的信息熵的计算如下: Entropy(t1)=−22log222−02log202=0
Entropy(t2)=−35log235−25log225=0.971
Entropy(t3)=−03log203−33log233=0
Entropy(t4)=−14log214−34log234=0.811
Entropy(t5)=−13log213−23log223=0.918
Entropy(t6)=−13log213−23log223=0.918
上述计算中我们定义0log20=0。 基于节点信息熵的定义,我们可以计算节点分裂前后的信息熵的下降值,称为**信息增益**(Information Gain):
InfoGain=Entropy(t0)−∑k=1KnknEntropy(tk)
收入水平分裂方案的 InfoGain=1−(210×0+510×0.971+310×0)=0.5145
教育程度分裂方案的 InfoGain=1−(410×0.811+310×0.918+310×0.918)=0.1248
我们挑选使得信息增益最大的特征进行分裂,所以挑选收入水平对根节点进行分裂。
信息增益有一个很大的缺点就是倾向于分裂很多样本数量很少的叶子节点,这样特别容易造成过拟合(模型在训练集上表现很好,在验证集上效果差)。为了解决这个问题,我们可以使用子节点的样本数量作为分裂信息对信息增益进行修正。
设n 为节点t0的样本数,nk为t0分裂生成的子节点tk的样本数。则分裂信息为
SplitInfo=−∑k=1Knknlog2(nkn)
我们用信息增益除以分裂信息就得到信息增益率(Information Gain Ratio):
InfoGainRatio=InfoGainSplitInfo=Entropy(t0)−∑k=1KnknEntropy(tk)−∑k=1Knknlog2(nkn)
使用信息增益率代替信息增益来平均分裂的好坏,能够避免分裂很多样本很少的子节点。
误分率
误分率是另外一种度量节点不纯度的方法。 假设数据集一共有C类,在节点t中第c类数据的相对频率为p(c|t),则节点t的误分率为
Error(t)=1−max(p(1|t),p(2|t),…,p(C|t))
误分率所代表的含义为,当按照多数类来预测当前节点样本的类别时,被错误分类的数据的比例。 当样本均匀地分布在每一个类别时,误差率取得最大值(1−1C),说明不纯度最大。 当样本都属于某一个类别时,误分率取得最小值0,说明不纯度最小。 对于表2中的3个示例节点,其误分率的计算如下:
Error(t1)=1−max(22,02)=0Error(t2)=1−max(35,25)=0.400Error(t3)=1−max(03,33)=0.
对于二分类问题,假设正类样本的相对频率为p,则负类样本的相对频率为1−p。 此时,上述三种不纯度度量指标分别为
Gini(p)=2p(1−p)Entropy(p)=−plog2p−(1−p)log2(1−p)Error(p)=1−max(p,1−p)
不纯度度量小结
Gini、信息熵、误分率是最为经典的不纯度度量方法。当子节点的样本相对频率为0或者1的时候,表示该节点样本类别一致,则不纯度都为0。而子节点的样本相对频率在0.5附近时,表示该节点样本类别均匀分布,此时,三种度量方法都达到最大值。
常见的决策树算法
从特征类型、不纯度度量或变量以及分割的选取方法和子节点分裂数量等维度研究者提出了很多决策树生成算法。本节我们对ID3、C4.5、CART和条件推断树这四种经典的决策树算法进行介绍。
ID3 和 C4.5
ID3(Iterative Dichotomiser 3)算法开创了决策树的先河。该算法使用信息熵度量节点不纯度,使用信息增益评价节点分裂好坏。然而,ID3算法只能处理离散型特征,对于连续型特征则通过枚举所有取值来分裂节点。由于ID3使用信息增益作为节点分裂的评价标准,该算法倾向于选取值比较多的特征并倾向于分裂很多样本数量很少的叶子节点,容易造成过拟合。
C4.5算法改进了ID3的上述缺点:
- 把每个分裂节点的样本量考虑进来,使用信息增益率来代替信息增益作为节点分裂评价标准,避免分裂较多的样本量少的子节点以及选择那些取值较多的特征。
- 通过分裂阈值来处理连续型特征,如身高,如果选取分裂阈值为170,则会分为两个子节点>170,<=170。
然而不论是ID3还是C4.5只能解决分类问题,而无法解决回归问题。
分类回归树(CART)
CART算法(Classification And Regression Tree,CART)既能解决分类问题又能解决回归问题。
- 解决分类问题时,节点不纯度采用Gini指数来度量,节点分裂评价采用Gini指数下降值。
- 解决回归问题实,节点不纯度采用目标特征的方差来度量,节点分裂评价标准采用方差下降值。
CART算法每次只分裂成两个子节点。
- 对于连续型特征,通过分裂阈值分裂成两个子节点,如身高,>170,<=170。
- 对于离散型特征,CART不再根据特征的所有取值分裂子节点,而是每次选择一个取值,根据是否为该取值来分裂节点。 例如,对于“收入水平”其取值范围为高中低{高,中,低}。 选取高{高}这一取值进行分裂,则会根据“收入水平高”和“收入水平不高”将节点分裂成两个子节点。
条件推断树(Conditional Inference Trees)
条件推断树(Conditional Inference Trees)与经典的决策树类似,但根据统计检验确定自变量和分割点的选择,而不是度量不纯度。 显著性检验是置换检验。
即先假设所有自变量与因变量相互独立,在对因变量和每个自变量进行卡房检验,计算出所有自变量的卡方值。选择p值小于阈值的自变量作为分裂特征,并将与因变量相关性最强的自变量作为根节点的分裂变量。自变量选择好后,用置换检验来选择分割点:选取一个划分点将一个自变量划分为两个部分,如果这两个部分有显著差异,则根据该分割点划分数据集。
与CART树类似,条件推断树每次也只分裂成两个子节点,但条件推断树不需要剪枝,因为阀值就决定了模型的复杂程度。所以如何决定阀值参数是非常重要的。
决策树算法总结
从特征类型、不纯度度量或变量以及分割的选取方法和子节点分裂数量等维度对上述三种常见的决策树算法进行了归纳总结。
算法特征类型目标类型变量和分割的选取子节点数量ID3离散型离散型不纯度度量:信息增益K>=2C4.5离散型、连续型离散型不纯度度量:信息增益率K >=2CART离散型,连续型离散型、连续型不纯度独立:GINI指数、方差K = 2条件推断树离散型,连续型离散型基于显著性检验K =2
决策树的剪枝
决策树如果不剪枝,就会生成非常复杂的树,这容易导致过拟合,即在训练集的预测准确率高,但是在验证集准确率低。因此在实际应用中,过于复杂的决策树性能往往很差。
我们需要使用剪枝(pruning)的方法来控制决策树生长过于复杂。根据剪枝策略是在决策树生成前还是生成后,可以分为两种:预剪枝(prepruning)和后剪枝(postpruning)。
- 预剪枝是我们事先设置一个不纯度下降的阈值,如果子节点的不纯度下降小于该阈值,则停止分裂。
- 后剪枝是指建立完整的决策树之后,再根据实际情况对决策树进行剪枝。
- 预剪枝非常简单,但是后剪枝效果更好。我们往往要根据不同的数据集,综合使用两种剪枝策略。
那么如何对决策树进行剪枝呢?
具体剪枝操作之前,我们需要定义判断整棵决策树优劣的指标,用以判断是否要进行具体剪枝操作。我们将其称为整体损失函数。
假设数据有C种类别,某一棵决策树T包含|T|个节点,其中节点t中的样本量为nt。设Imp(t)为节点t的不纯度度量方法(例如基尼、信息熵和误分率),那么损失函数可表示为:
Costα(T)=∑t=1|T|ntImp(t)+α|T|
这一损失函数包含两项:第一项表示模型对训练集的拟合度,第二项是模型复杂度。两者是此消彼长的关系。
我们最小化这个总体的损失函数,可以对拟合度和复杂度做一个权衡(即偏差和方差的tradeoff)。复杂度的控制参数α,代表了我们对生成复杂决策树的惩罚力度。
决策树分析
决策树实质上是IF-THEN规则的集合,这种规则与人类进行决策的行为习惯不谋而合,这使得决策树具有很强的可解释性。另外,我们可以将决策树模型进行可视化,更能有效地帮助我们分析和解决问题。 强可解释性和易于可视化使得决策树模型在金融领域、健康医疗领域、工业生产和制造、天文学和分子生物学得到了广泛应用等。
本文荟萃自知乎 公众号:汉森定理,只做学术交流学习使用,不做为临床指导,本文观点不代表数字重症 ICU.CN立场。
 微信扫一扫
微信扫一扫