背景:
在重症监护病房(ICU)中,患者病情变化迅速,及时准确地预测短期死亡风险至关重要。传统评分系统,如简化急性生理评分(SAPS)和急性生理与慢性健康评估(APACHE),依赖于入院后前24小时内采集的静态变量,未能反映患者不断演变的临床状态。这些系统缺乏实时适应性、可解释性和广泛适用性。随着高频电子病历(EMR)数据的日益普及,机器学习(ML)方法已成为建模复杂时间模式、辅助动态临床决策的重要工具。然而,现有模型普遍存在无法有效处理不规则采样和缺失值的问题,且多数缺乏跨机构的严格外部验证。
研究目的:
本研究旨在构建一个可实时更新、具有可解释性且具备更强泛化能力的风险预测模型,能够基于不规则的纵向EMR数据,持续动态地评估ICU患者的死亡风险,优于传统静态评分系统的表现。
方法:
我们基于MIMIC-IV(重症监护医学信息数据库)与eICU合作研究数据库(eICU-CRD)中的176,344次ICU住院记录,开发了一种时间感知的双向注意力机制长短期记忆网络(TBAL)模型。该模型融合了动态变量,包括生命体征、实验室检查结果与用药信息,并以小时为单位进行更新,实现静态与动态死亡风险的双重评估。通过外部交叉验证与亚组敏感性分析评估模型的稳健性与公平性,模型性能通过ROC曲线下面积(AUROC)、精确-召回曲线下面积(AUPRC)、准确率与F1分数进行评价。模型可解释性通过集成梯度方法突出关键预测因子。
结果:
在静态的12小时至1天死亡预测任务中,TBAL模型在MIMIC-IV与eICU-CRD数据集中分别取得了95.9(95% CI: 94.2-97.5)与93.3(95% CI: 91.5-95.3)的AUROC,以及48.5与21.6的AUPRC。准确率与F1分数分别为94.1与46.7(MIMIC-IV)以及92.2与28.1(eICU-CRD)。在动态预测任务中,AUROC分别为93.6(95% CI: 93.2-93.9)与91.9(95% CI: 91.6-92.1),AUPRC为41.3与50。模型在阳性病例中保持较高召回率(MIMIC-IV为82.6%,eICU-CRD为79.1%)。跨数据库验证显示AUROC分别为81.3与76.1,证实了其泛化能力。亚组分析显示模型在不同年龄、性别和疾病严重程度群体中表现稳定,关键预测因子包括乳酸水平、升压药使用与格拉斯哥昏迷评分。
结论:
TBAL模型为ICU患者提供了一种稳健、可解释且具备良好泛化能力的动态实时死亡风险预测方案。其对不规则时间序列的适应能力以及每小时更新预测的特性,使其成为一款有前景的临床决策支持工具。未来的工作应进一步在前瞻性临床试验中验证其有效性,并探索其在实际ICU工作流程中的整合应用,以提升患者预后。
一、先行研究
-
传统方法:ICU中广泛使用的传统评分系统,如SAPS(Simplified Acute Physiology Score)和APACHE(Acute Physiology and Chronic Health Evaluation),用于评估疾病严重程度和预测死亡风险。
-
机器学习方法兴起:近年来,ML方法(如梯度提升机、CNN、LSTM)在ICU死亡预测方面显示出优于传统评分系统的性能,具备处理大规模、高维、异质性医疗数据的能力 。
二、先行研究的缺点
-
静态性:传统评分系统和许多ML模型主要基于入院前24小时的静态数据,未能反映患者病情的动态变化 。
-
特征处理方式粗糙:大量ML模型依赖手工构造特征或固定时间窗口汇总,难以捕捉细粒度的时间变化趋势与生理状态演变。
-
时间序列建模能力不足:现有方法难以有效处理EMR数据中存在的时间不规则性和缺失值问题,大多假设数据为规则采样,需依赖插补,可能引入误差。
-
泛化性差:大多数模型仅在特定数据集上训练和验证,缺乏多中心外部验证,临床应用的稳健性和广泛适用性不足。
三、选题原因
-
临床现实需求:ICU患者病情变化快,死亡风险在24小时内波动明显,传统方法难以满足“实时、连续、个体化”的风险评估需求。
-
数据资源可得性增强:随着高频EMR系统的发展,纵向动态数据变得更加丰富,为实现动态预测提供了数据基础。
-
现有模型缺口:缺乏能够适应EMR时间不规则性、连续建模、具备良好泛化能力的实时预测工具,存在明显研究空白与应用价值。
四、本研究的创新点
-
时间感知+双向注意力机制LSTM框架(TBAL):采用专门设计的深度学习结构,可同时捕捉时间间隔信息与变量之间的动态依赖关系。
-
支持不规则、纵向数据的实时建模:突破了传统模型对固定时间窗与规则采样的依赖,能动态反映病情变化。
-
解释性设计:结合注意力机制和集成梯度方法,提供可解释的预测结果,便于临床医生理解和信任。
-
跨中心验证:在MIMIC-IV和eICU-CRD等多中心数据集上进行建模与验证,增强模型的泛化能力和临床可推广性。
数据来源
本研究使用两个公开电子病历数据库:MIMIC-IV 和 eICU-CRD,均包含 ICU 患者的纵向、不规则临床数据(如生命体征、化验结果、用药与液体出入量)。
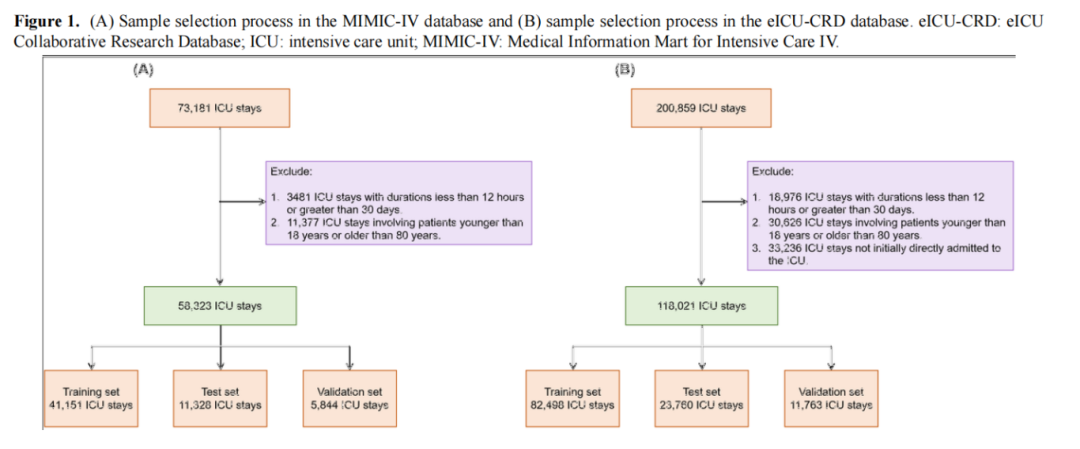
MIMIC-IV 收录了2008–2019年在波士顿贝斯以色列女执事医疗中心 ICU 或急诊就诊患者的记录,共提取 73,181 次 ICU 住院(50,920 名患者),以 “stay_id” 标识。
eICU-CRD 包含 2014–2015 年美国 200 家 ICU 单位的记录,提取 200,859 次住院(139,367 名患者),以 “patientunitstayid” 标识。
我们以 ICU 住院为分析单位,排除住院时间少于 12 小时或超过 30 天者,以及年龄小于 18 岁或大于 80 岁者。最终纳入 MIMIC-IV 数据 58,323 条,eICU-CRD 数据 118,021 条。图 1 展示了样本筛选流程。
为统一两个数据库中的临床变量定义,我们采用了两个权威映射工具:eicu-code(用于 eICU-CRD)与 mimic-code(用于 MIMIC-IV),对变量与编码进行统一,确保临床概念一致性与数据可比性 。
研究数据包括患者人口统计信息、病史、化验结果、生命体征、用药、尿量及机械通气状态。除人口学信息外,其他均为纵向、不规则时间序列数据。为处理这类数据,我们参考了 EMR-LIP 框架,结合临床专家意见构建变量词典,定义每个变量的数据类型、聚合方法与缺失值填补策略(详见附录表 S5 与 S6)。聚合与填补方式依据变量特性设计,更符合临床实践。相较于直接用 0 占位以便模型自动学习缺失模式的方式,该方法更具可解释性。
为统一动态变量的时间轴,我们将时间线按小时离散,从 ICU 入院起至出院止。各变量按每小时重采样,若在 [ti−0.5, ti+0.5] 内存在多个观测值,则根据变量词典采用如中位数(数值型)或众数(类别型)等方法聚合;若无观测,则标记为缺失。
我们引入了掩码矩阵 mt,d 表示变量 xd 在时间 ti 是否被观测,mt,d=1 表示有值,mt,d=0 表示缺失。为保留重采样后的时间间隔信息,另构建时间间隔向量 δt,记录每个变量自上一次观测以来的时间差(详见附录)。
缺失值填补按变量类型与缺失位置采用不同策略:
-
对于首次观测缺失,使用前向填补(LOCF);
-
若整个住院期间无观测,则用训练集中的中位数或众数填补;
-
其他缺失值,数值型采用线性插值,类别型设为“缺失”一类;
-
若某时刻 ti 所有变量均缺失,则删除该时间点。
本研究旨在建立一个用于 ICU 患者院内死亡预测的动态连续风险评估模型,任务包括固定时间点触发的静态预测与持续更新的动态预测,两者主要区别在于预测时间窗是否随时间推移而更新。
在静态任务中,我们以 ICU 入院后第12小时为起点,预测从该时间点起的不同时间范围内的死亡风险(如12小时至1日、12小时至7日等)及 ICU 住院超过2天的风险。动态任务则在每小时预测未来24小时内的死亡可能性。
基础模型为 LSTM,具备处理时间序列的能力。为进一步优化性能,我们提出了 TBAL 模型(时间感知双向注意力LSTM),在 LSTM 基础上引入两大关键机制:
-
双向LSTM 捕捉前向与后向的时间依赖;
-
时间感知注意力机制 为不同时间点的特征动态赋权,强化对关键信息的关注。
TBAL 可处理多变量时间序列数据,提供小时级实时预测,兼顾精度与模型复杂度。在模型训练时,我们以 ICU 住院为样本单位,但按患者分组划分训练集、验证集与测试集(7:2:1),以避免同一患者的多次住院记录造成数据泄漏。
为提升模型泛化能力,我们识别了 MIMIC-IV 与 eICU-CRD 两数据库中定义一致的34个动态变量,并在各自数据库中分别训练与测试静态和动态任务,同时进行交叉测试。
模型未采用网格搜索调参,而是设定较大的模型容量(如 LSTM 隐藏单元为512),并结合 L2 正则化与早停机制防止过拟合。TBAL 模型参数量为 727,640,推理时占用内存约 2.79MB,可在普通 CPU 上运行,实测推理速度为每秒 35 次,具备临床应用中的实时预测能力。
针对标签不平衡问题,静态任务中采用批次平衡采样策略,确保每轮梯度更新中正负样本数量相当。动态任务则通过在交叉熵损失中引入类别权重因子进行平衡,权重按类别比例的倒数归一化设定,提升模型对少数类的敏感性。
为解决深度学习模型“黑箱”特性带来的可解释性问题,我们采用了集成梯度法(Integrated Gradients, IG)。IG 是一种广泛认可的特征归因方法,能够量化每个输入特征对模型预测结果的贡献。其基本原理是:计算从一个基线输入到实际输入这一路径上,模型输出相对于各输入特征的梯度,并对这些梯度进行积分。该方法能以系统性的方式估算特征的重要性,体现每个特征在预测结果中的“增量效应”。
与其他归因方法不同,IG 满足完备性(completeness)和敏感性(sensitivity)等关键数学性质,使其成为理解模型预测机制的一种稳健选择。通过引入 IG,我们旨在识别和解释驱动模型决策的关键特征,实现输入特征与预测结果之间的透明关联。
具体而言,对于输入xx 和模型FF,集成梯度 IG 定义如下:
IGi(x)=(xi−xi′)×∫01∂F(x′+α(x−x′))∂xidα
其中,x′x’ 为基线输入,alphaα表示从基线到实际输入的路径。在实际操作中,该积分通过数值方法近
我们采用多种评估指标对模型性能进行评估,包括受试者工作特征曲线下面积(AUROC)、精确-召回曲线下面积(AUPRC)、准确率、召回率、精确率和F1 分数。同时,我们在不同亚组中(按性别、年龄和种族划分)进行了广泛的敏感性分析。
对于动态预测任务,我们还评估了模型在不同时间点的表现。
其中,TP 表示真正例,TN 表示真负例,FP 表示假正例,FN 表示假负例。所有评估指标的 95% 置信区间(CI)均通过“1000次自助法(bootstrap)”抽样估计获得。
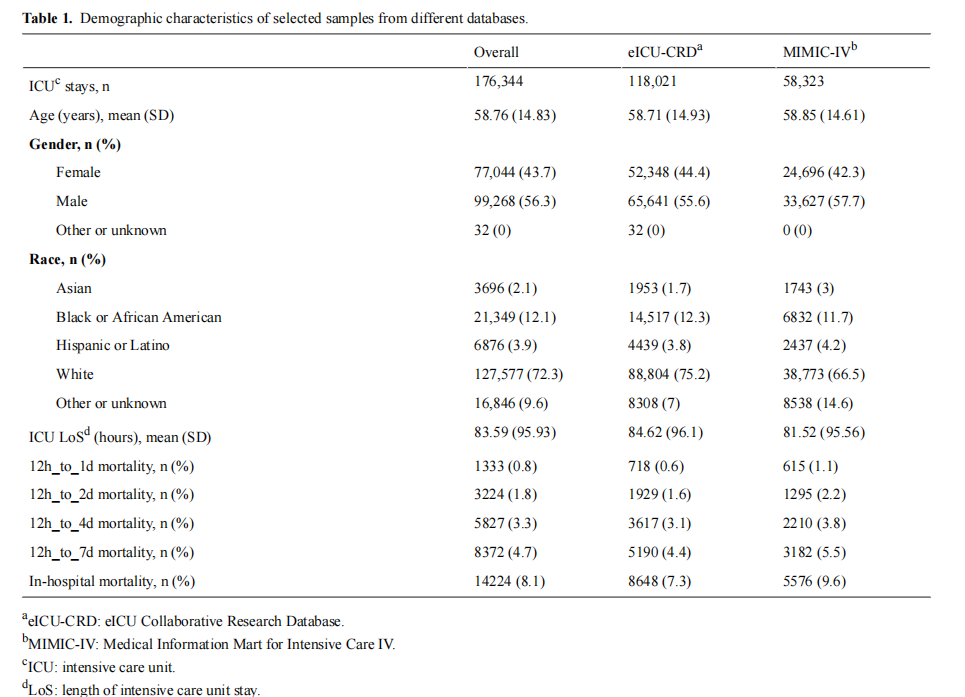
我们共纳入来自两个数据库的 176,344 条 ICU 住院记录,其中 MIMIC-IV 数据库58,323 条,eICU-CRD 数据库118,021 条。表1展示了以 ICU 住院为单位的患者基线特征。总体院内死亡率为 8.1%,其中 MIMIC-IV 为 9.6%,eICU-CRD 为 7.3%。
在 ICU 入院后第12小时触发的静态任务中(如12小时至1日、2日、4日、7日死亡率预测,12小时后院内死亡,ICU住院超过2天等),TBAL 模型性能均优于基线 LSTM 模型。
以 12 小时至 1 日死亡预测为例,TBAL 的 AUROC 在 MIMIC-IV 中达到 95.9(95% CI: 94.2–97.5),在 eICU-CRD 中为 93.3(95% CI: 91.5–95.3)。更多详细性能见表2。
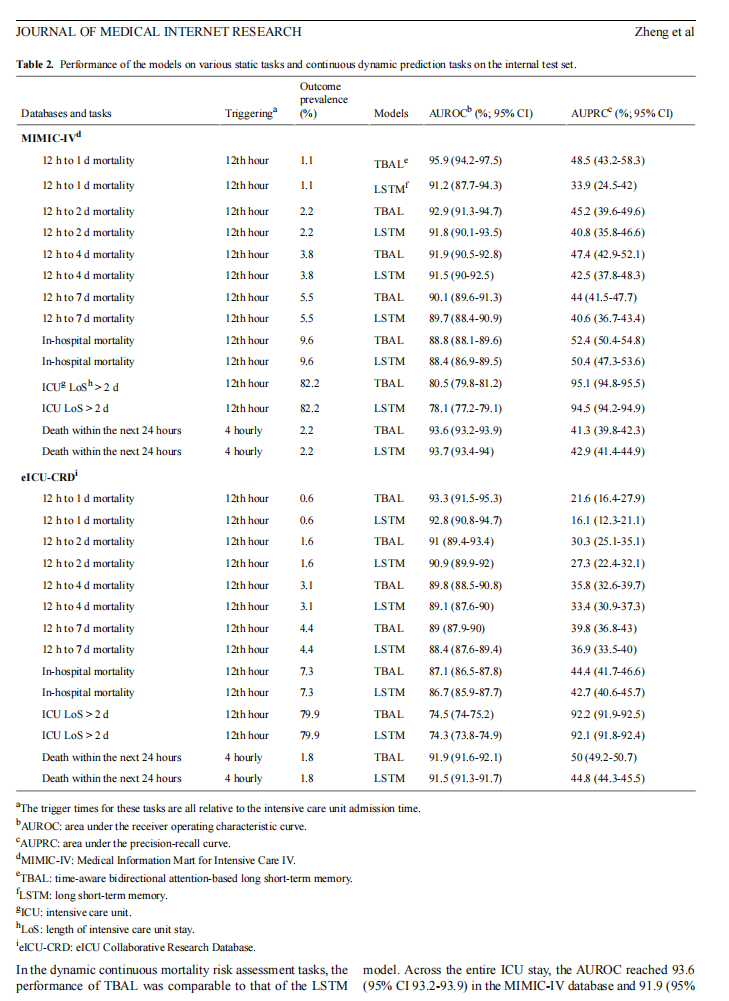
我们还以每 4 小时为间隔分析模型性能在 ICU 住院过程中的变化。结果表明,模型性能随时间推移逐渐提升:ICU 入住初期 AUROC 较低,出院时 TBAL 在 MIMIC-IV 上 AUROC 达98.9(95% CI: 98.6–99.2),AUPRC 达92.1(95% CI: 90.6–93.7);在 eICU-CRD 上 AUROC 为95.4(95% CI: 95.0–95.9),AUPRC 为71.3(95% CI: 69.3–73.8)。
尽管在 AUPRC 指标上存在一定差异,两库总体性能一致,这可能与两个数据库中变量集的差异有关。动态任务在各时间点的性能对比如图2所示。
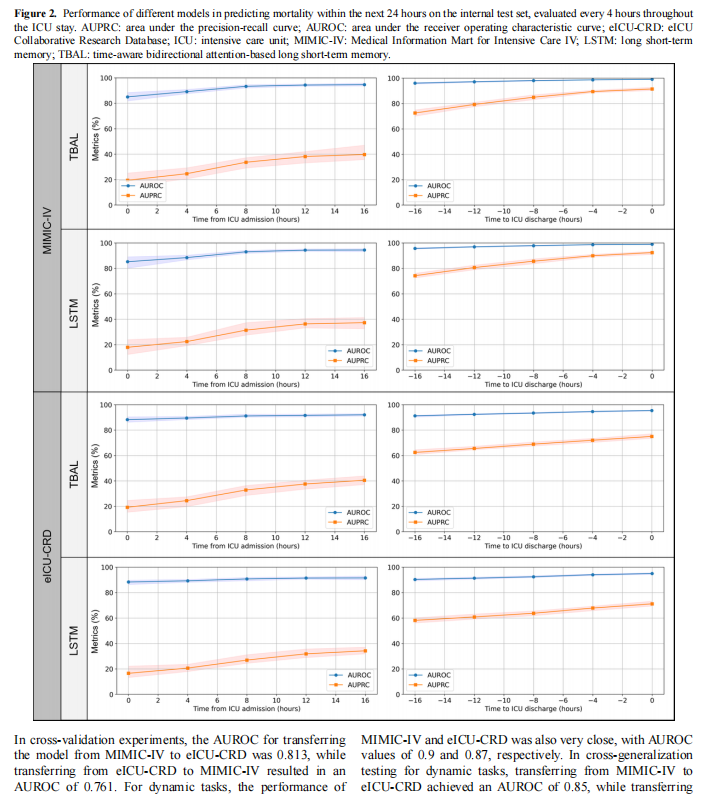
跨数据库泛化性能
在交叉验证实验中,将模型从 MIMIC-IV 应用于 eICU-CRD 的 AUROC 为 0.813,反向转移时 AUROC 为 0.761。动态任务中,两库模型性能相近,AUROC 分别为 0.90 与 0.87。在跨库动态泛化测试中,从 MIMIC-IV 转移至 eICU-CRD 的 AUROC 为 0.85,反之为 0.83。相关结果见图3。
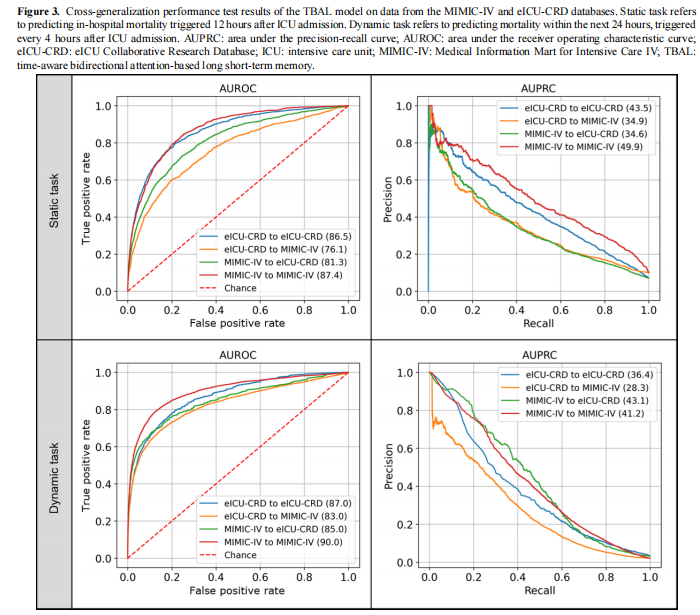
亚组分析结果
我们对不同性别、年龄和种族群体在静态与动态任务中的模型性能进行了分析(见表3)。
-
年龄:模型在
-
性别:男女之间表现较为平衡;
-
种族:尽管不同种族间存在细微差异,但 AUROC 与 AUPRC 的 95% 置信区间存在重叠,差异不具统计学显著性。总体来看,模型在各亚群体间具有良好的适应性。
特征重要性解释
我们采用集成梯度(IG)方法,在静态与动态任务中评估模型对每位患者的特征归因。图4展示了特征重要性排序。
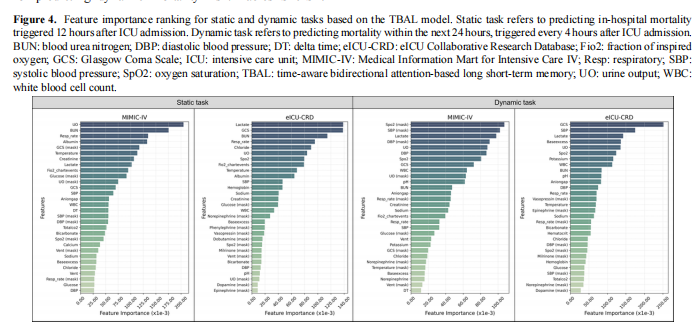
-
在静态任务中,MIMIC-IV 数据库中重要特征包括:血尿素氮、尿量、呼吸频率、乳酸、体温;eICU-CRD 中则为:乳酸、格拉斯哥昏迷评分、血尿素氮、呼吸频率、尿量,两个数据库前20个关键变量有高度重合,主要为生理和实验室指标。
-
在动态任务中,MIMIC-IV 中关键特征包括:SpO₂、收缩压、乳酸、舒张压;eICU-CRD 中为:格拉斯哥昏迷评分、收缩压、乳酸、碱剩余、尿量。相比静态任务,动态任务中“升压药使用(如去甲肾上腺素或加压素)”重要性更高,表明其对动态死亡风险预测的显著关联。
END
学术交流文章,不做为临床依据,特此声明。发布者:Chu,转转请注明出处:https://www.icu.cn/?p=17937
 微信扫一扫
微信扫一扫